반응형
#Nvidia Developer, 단 몇 시간 만에 새로운 기술을 배우세요, 2
#00_Introduction.ipynb
소개만 몇시간을 보고 있습니다. 아래 순서대로 공부하면 됩니다.
#01_ExploreData.ipynb
#02_PrepareData.ipynb
#03_BuildModel.ipynb
#Introduction
The goal of this lab is to build an example deep neural network that can predict future outcomes based on time series, or sequential, data.
A time series is a series of data points, ordered in time. For complex systems, each data point will likely be multivariate, meaning there are multiple variables for each data point. Examples of data sets with multivariate time series data are financial markets, air quality measurement, and health records. In each case, the goal is to predict one of the variable values, such as a stock price, pollutant level, or patient outcome, based on the sequential dependence of past data.
In this lab, you'll build a deep neural network model to predict patient mortality from time series data contained in patient records.
The purpose of building such a model, is to provide an analytic framework that medical professionals can use to predict patient mortality at any time of interest. Such a solution provides essential feedback to clinicians when trying to assess the impact of treatment decisions, or raise early warning signs to flag at-risk patients in a busy hospital care setting.
This project and patient electronic health record (EHR) data are provided by Children's Hospital Los Angeles (CHLA).

#이 실험실의 목표는 시계열 또는 순차적 데이터를 기반으로 미래 결과를 예측할 수 있는 예제 딥 뉴럴 네트워크를 구축하는 것입니다.
시계열 데이터는 시간 순서대로 정렬된 일련의 데이터 포인트입니다. 복잡한 시스템의 경우 각 데이터 포인트는 다변수일 가능성이 높으며, 이는 각 데이터 포인트에 여러 변수가 존재한다는 것을 의미합니다. 다변수 시계열 데이터 세트의 예로는 금융 시장, 대기 질 측정 및 건강 기록 등이 있습니다. 이러한 각 경우의 목표는 과거 데이터의 순차적 의존성을 기반으로 주식 가격, 오염 물질 수준 또는 환자 결과와 같은 변수 값 중 하나를 예측하는 것입니다.
이 실험실에서는 환자 기록에 포함된 시계열 데이터를 사용하여 환자 사망률을 예측하는 딥 뉴럴 네트워크 모델을 구축하게 됩니다.
이러한 모델을 구축하는 목적은 의료 전문가들이 관심 있는 시점에서 환자 사망률을 예측할 수 있는 분석 프레임워크를 제공하는 것입니다. 이러한 솔루션은 치료 결정의 영향을 평가하거나 바쁜 병원 진료 환경에서 고위험 환자를 식별하기 위한 조기 경고 신호를 제공하는 데 필수적인 피드백을 임상의에게 제공합니다.
이 프로젝트와 환자 전자 건강 기록(EHR) 데이터는 로스앤젤레스 어린이 병원(CHLA)에서 제공됩니다.
#timeseries_keras_v1p0p0_Modeling Time Series Data with Recurrent Neural Networks in Keras
timeseries_keras_v1p0p0_Modeling Time Series Data with Recurrent Neural Networks in Keras.pdf
1.15MB
timeseries_keras_v1p0p0_Modeling Time Series Data with Recurrent Neural Networks in Keras.pptx
2.65MB
#Next
#To get started with this GPU Task please click the "Start" button on the top right of this block. New info will appear here once you do.
#이 GPU 작업을 시작하려면 이 블록의 오른쪽 상단에 있는 "Start" 버튼을 클릭하세요. 클릭하면 여기에 새 정보가 나타납니다.
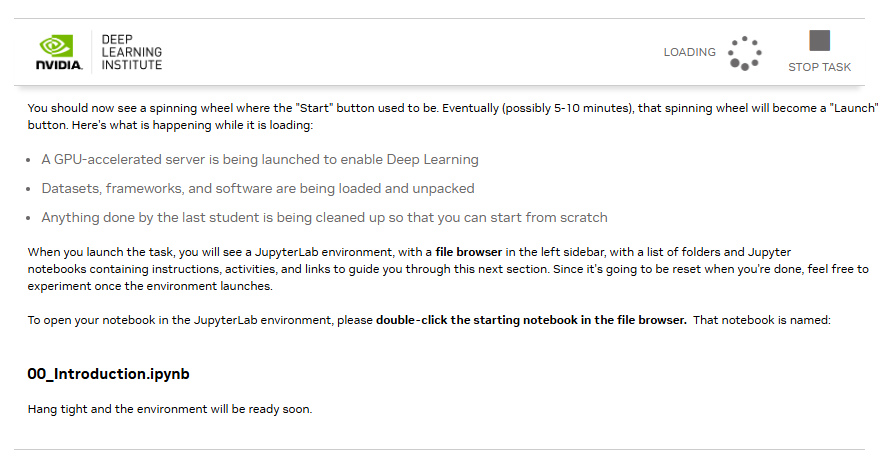
#You should now see a spinning wheel where the "Start" button used to be. Eventually (possibly 5-10 minutes), that spinning wheel will become a "Launch" button. Here's what is happening while it is loading:
- A GPU-accelerated server is being launched to enable Deep Learning
- Datasets, frameworks, and software are being loaded and unpacked
- Anything done by the last student is being cleaned up so that you can start from scratch
When you launch the task, you will see a JupyterLab environment, with a file browser in the left sidebar, with a list of folders and Jupyter notebooks containing instructions, activities, and links to guide you through this next section. Since it's going to be reset when you're done, feel free to experiment once the environment launches.
To open your notebook in the JupyterLab environment, please double-click the starting notebook in the file browser. That notebook is named:
00_Introduction.ipynb
Hang tight and the environment will be ready soon.
#이제 "Start" 버튼이 있던 자리에 회전하는 바퀴가 보일 것입니다. 잠시 후(5~10분 정도 소요될 수 있음) 해당 바퀴는 "Launch" 버튼으로 변경됩니다. 다음은 로드되는 동안 일어나는 일입니다:
딥러닝을 가능하게 하기 위해 GPU 가속 서버가 실행 중입니다.
데이터셋, 프레임워크 및 소프트웨어가 로드되고 압축 해제됩니다.
마지막 학생이 수행한 작업이 정리되어 처음부터 다시 시작할 수 있습니다.
작업을 시작하면 왼쪽 사이드바에 파일 탐색기가 있는 주피터랩 환경이 표시되며, 폴더와 지침, 활동 및 다음 섹션을 안내하는 링크가 포함된 주피터 노트북 목록이 표시됩니다. 작업이 완료되면 재설정되므로 환경이 시작되면 자유롭게 실험해 보세요.
주피터랩 환경에서 노트북을 열려면 파일 탐색기에서 시작 노트북을 두 번 클릭하세요. 해당 노트북의 이름은 다음과 같습니다:
00_Introduction.ipynb
잠시만 기다려 주시면 환경이 곧 준비될 것입니다.
#00_Introduction.ipynb
#00_Introduction.ipynb
#Modeling Time Series Data with Recurrent Neural Networks in Keras
The goal of this lab is to build an example deep neural network that can predict future outcomes based on time series, or sequential, data.
A time series is a series of data points, ordered in time. For complex systems, each data point will likely be multivariate, meaning there are multiple variables for each data point. Examples of data sets with multivariate time series data are financial markets, air quality measurement, and health records. In each case, the goal is to predict one of the variable values, such as a stock price, pollutant level, or patient outcome, based on the sequential dependence of past data.
In this lab, you'll build a deep neural network model to predict patient mortality from time series data contained in patient records.
The purpose of building such a model, is to provide an analytic framework that medical professionals can use to predict patient mortality at any time of interest. Such a solution provides essential feedback to clinicians when trying to assess the impact of treatment decisions, or raise early warning signs to flag at-risk patients in a busy hospital care setting.
This project and patient electronic health record (EHR) data are provided by Children's Hospital Los Angeles (CHLA).
#케라스를 사용한 순환 신경망으로 시계열 데이터 모델링
이 실험실의 목표는 시계열 또는 순차적 데이터를 기반으로 미래 결과를 예측할 수 있는 예제 심층 신경망을 구축하는 것입니다.
시계열은 시간 순서대로 나열된 데이터 포인트의 시리즈입니다. 복잡한 시스템의 경우 각 데이터 포인트는 다변량일 가능성이 높으며, 이는 각 데이터 포인트에 여러 변수가 있음을 의미합니다. 다변량 시계열 데이터를 포함하는 데이터셋의 예로는 금융 시장, 대기 질 측정 및 건강 기록이 있습니다. 각 경우에서의 목표는 과거 데이터의 순차적 의존성을 기반으로 주식 가격, 오염 물질 수치 또는 환자 결과와 같은 변수 중 하나를 예측하는 것입니다.
이 실험실에서는 환자 기록에 포함된 시계열 데이터를 사용하여 환자 사망률을 예측하는 심층 신경망 모델을 구축할 것입니다.
이미지
이러한 모델을 구축하는 목적은 의료 전문가들이 관심 있는 시점에서 환자 사망률을 예측할 수 있는 분석 프레임워크를 제공하는 것입니다. 이러한 솔루션은 치료 결정의 영향을 평가하려고 할 때나 바쁜 병원 환경에서 위험에 처한 환자를 조기에 경고하는 데 필수적인 피드백을 임상 의사들에게 제공할 수 있습니다.
이 프로젝트와 환자 전자 건강 기록(EHR) 데이터는 로스앤젤레스 어린이 병원(CHLA)에서 제공됩니다.
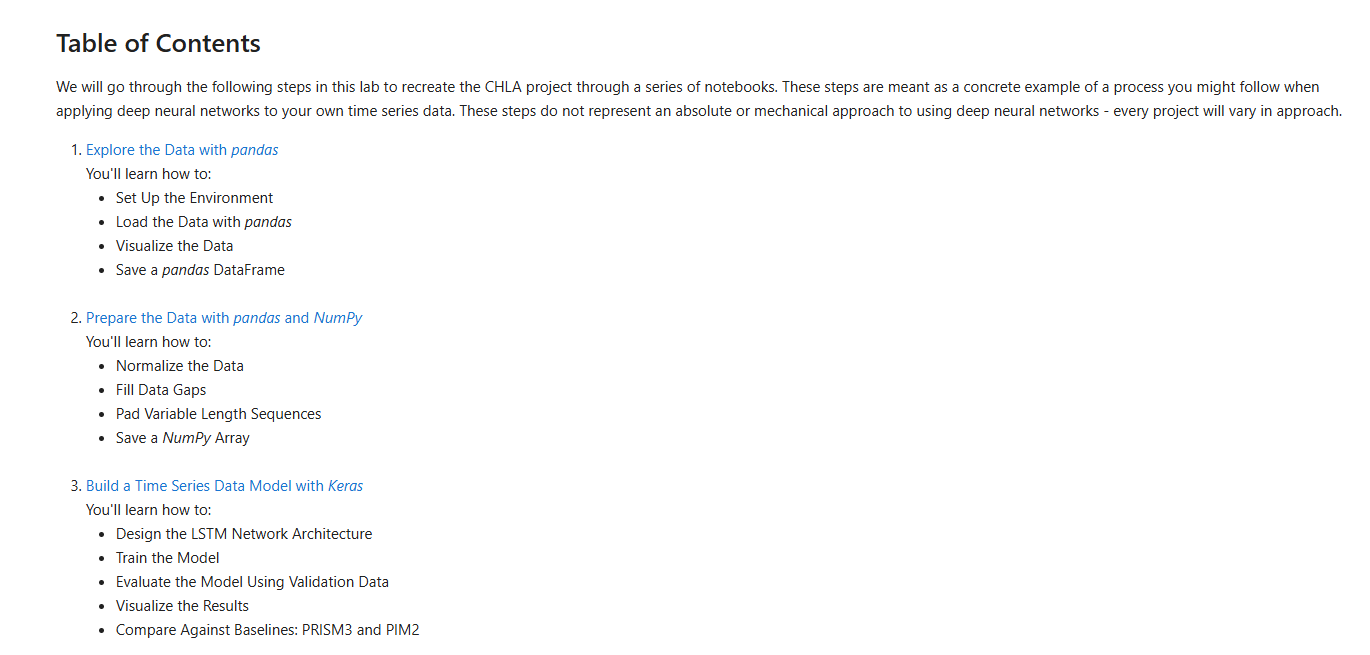
#Table of Contents
We will go through the following steps in this lab to recreate the CHLA project through a series of notebooks. These steps are meant as a concrete example of a process you might follow when applying deep neural networks to your own time series data. These steps do not represent an absolute or mechanical approach to using deep neural networks - every project will vary in approach.
- Explore the Data with pandas
You'll learn how to:- Set Up the Environment
- Load the Data with pandas
- Visualize the Data
- Save a pandas DataFrame
- Prepare the Data with pandas and NumPy
You'll learn how to:- Normalize the Data
- Fill Data Gaps
- Pad Variable Length Sequences
- Save a NumPy Array
- Build a Time Series Data Model with Keras
You'll learn how to:- Design the LSTM Network Architecture
- Train the Model
- Evaluate the Model Using Validation Data
- Visualize the Results
- Compare Against Baselines: PRISM3 and PIM2
#목차
이 실험실에서는 일련의 노트북을 통해 로스앤젤레스 어린이 병원(CHLA) 프로젝트를 재현하기 위해 다음 단계를 진행할 것입니다. 이러한 단계는 심층 신경망을 본인의 시계열 데이터에 적용할 때 따를 수 있는 프로세스의 구체적인 예로 만들어졌습니다. 이러한 단계는 절대적이거나 기계적인 접근 방식을 나타내는 것은 아닙니다. 모든 프로젝트는 접근 방식이 다를 것입니다.
pandas로 데이터 탐색하기
다음 사항을 배울 것입니다:
- 환경 설정하기
- pandas로 데이터 로드하기
- 데이터 시각화하기
- pandas DataFrame 저장하기
pandas와 NumPy로 데이터 준비하기
다음 사항을 배울 것입니다:
- 데이터 정규화하기
- 데이터 간격 채우기
- 가변 길이 시퀀스 패딩하기
- NumPy 배열 저장하기
케라스로 시계열 데이터 모델 구축하기
다음 사항을 배울 것입니다:
- LSTM 네트워크 아키텍처 설계하기
- 모델 훈련시키기
- 검증 데이터를 사용하여 모델 평가하기
- 결과 시각화하기
- PRISM3 및 PIM2와 비교하기
#JupyterLab
For this hands-on lab, we use JupyterLab to manage our environment. The JupyterLab Interface is a dashboard that provides access to interactive iPython notebooks, as well as the folder structure of our environment and a terminal window into the Ubuntu operating system. The first view you'll see includes a menu bar at the top, a file browser in the left sidebar, and a main work area that is initially open to the "Launcher" page.
#JupyterLab
이 실습에서는 JupyterLab을 사용하여 환경을 관리합니다. JupyterLab 인터페이스는 대화형 iPython 노트북에 접근할 수 있는 대시보드를 제공하며, 환경의 폴더 구조와 Ubuntu 운영 체제의 터미널 창도 제공합니다. 처음 보게 되는 화면에는 상단의 메뉴 바, 왼쪽 사이드바의 파일 탐색기 및 초기에는 "런처" 페이지로 열려 있는 주요 작업 영역이 포함되어 있습니다.
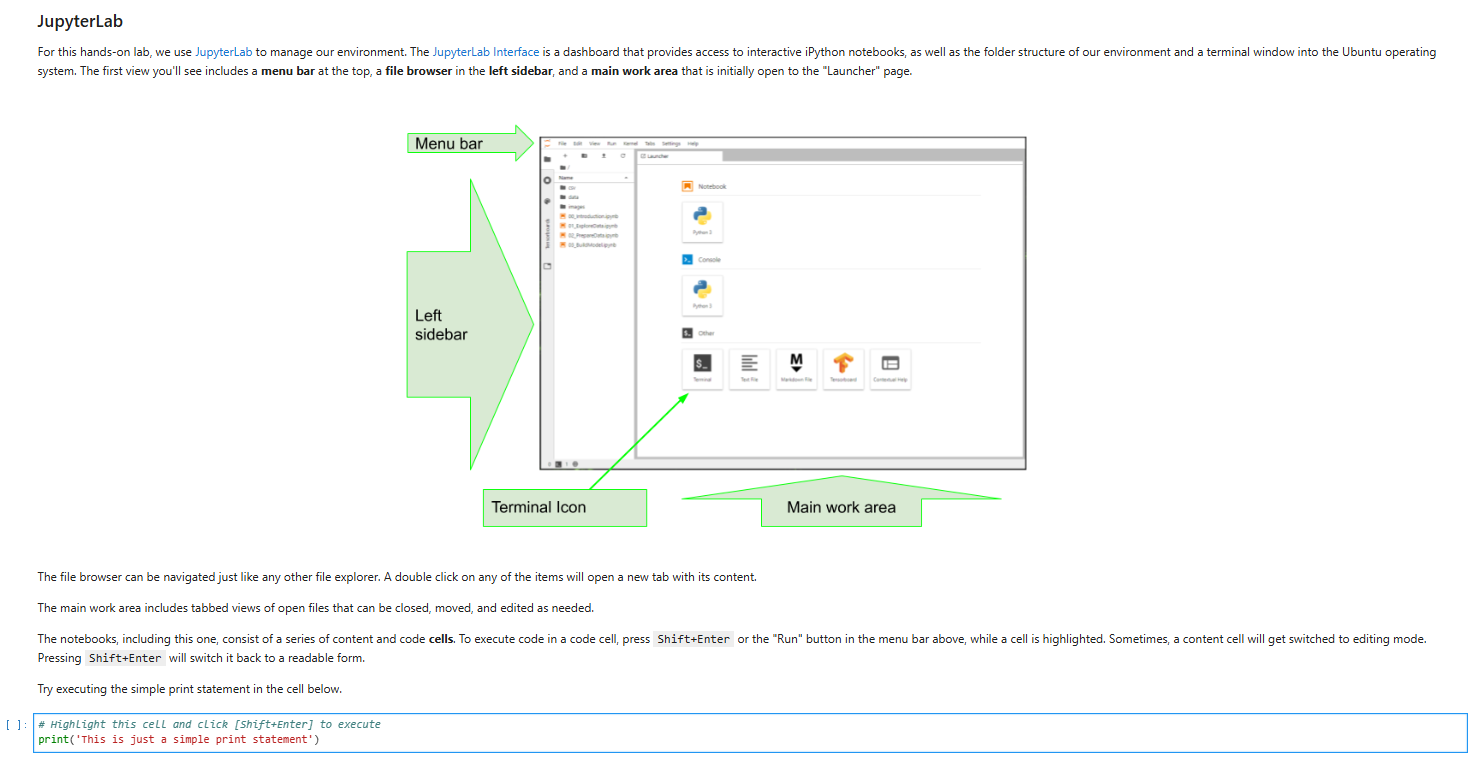
#The file browser can be navigated just like any other file explorer. A double click on any of the items will open a new tab with its content.
The main work area includes tabbed views of open files that can be closed, moved, and edited as needed.
The notebooks, including this one, consist of a series of content and code cells. To execute code in a code cell, press Shift+Enter or the "Run" button in the menu bar above, while a cell is highlighted. Sometimes, a content cell will get switched to editing mode. Pressing Shift+Enter will switch it back to a readable form.
Try executing the simple print statement in the cell below.
#파일 탐색기는 다른 파일 탐색기와 마찬가지로 탐색할 수 있습니다. 항목을 더블 클릭하면 해당 항목의 내용이 포함된 새 탭이 열립니다.
주요 작업 영역에는 열린 파일의 탭 형식 뷰가 포함되며, 이를 필요에 따라 닫고, 이동하고, 편집할 수 있습니다.
이 노트북을 포함하여 노트북은 일련의 콘텐츠 셀과 코드 셀로 구성되어 있습니다. 코드 셀에서 코드를 실행하려면 셀이 강조 표시된 상태에서 Shift+Enter를 누르거나 위의 메뉴 바에 있는 "실행" 버튼을 누릅니다. 가끔씩 콘텐츠 셀이 편집 모드로 전환될 수 있습니다. Shift+Enter를 누르면 다시 읽기 가능한 형태로 전환됩니다.
아래 셀에서 간단한 print 문을 실행해 보십시오.
# Highlight this cell and click [Shift+Enter] to execute
print('This is just a simple print statement')
#
# 이 셀을 강조 표시하고 Shift+EnterShift+Enter를 클릭하여 실행하십시오.
print('이것은 단순한 출력문입니다')#메뉴얼을 익히자.
#JupyterLab Documentation(클릭)
Welcome to the JupyterLab documentation site. JupyterLab is a highly extensible, feature-rich notebook authoring application and editing environment, and is a part of Project Jupyter, a large umbrella project centered around the goal of providing tools (and standards) for interactive computing with computational notebooks.
A computational notebook is a shareable document that combines computer code, plain language descriptions, data, rich visualizations like 3D models, charts, graphs and figures, and interactive controls. A notebook, along with an editor like JupyterLab, provides a fast interactive environment for prototyping and explaining code, exploring and visualizing data, and sharing ideas with others.
JupyterLab is a sibling to other notebook authoring applications under the Project Jupyter umbrella, like Jupyter Notebook and Jupyter Desktop. JupyterLab offers a more advanced, feature rich, customizable experience compared to Jupyter Notebook.
Try JupyterLab on Binder. JupyterLab follows the Jupyter Community Guides.
#The JupyterLab Interface(클릭)
JupyterLab provides flexible building blocks for interactive, exploratory computing. While JupyterLab has many features found in traditional integrated development environments (IDEs), it remains focused on interactive, exploratory computing.
The JupyterLab interface consists of a main work area containing tabs of documents and activities, a collapsible left sidebar, and a menu bar. The left sidebar contains a file browser, the list of running kernels and terminals, the command palette, the notebook cell tools inspector, and the tabs list.
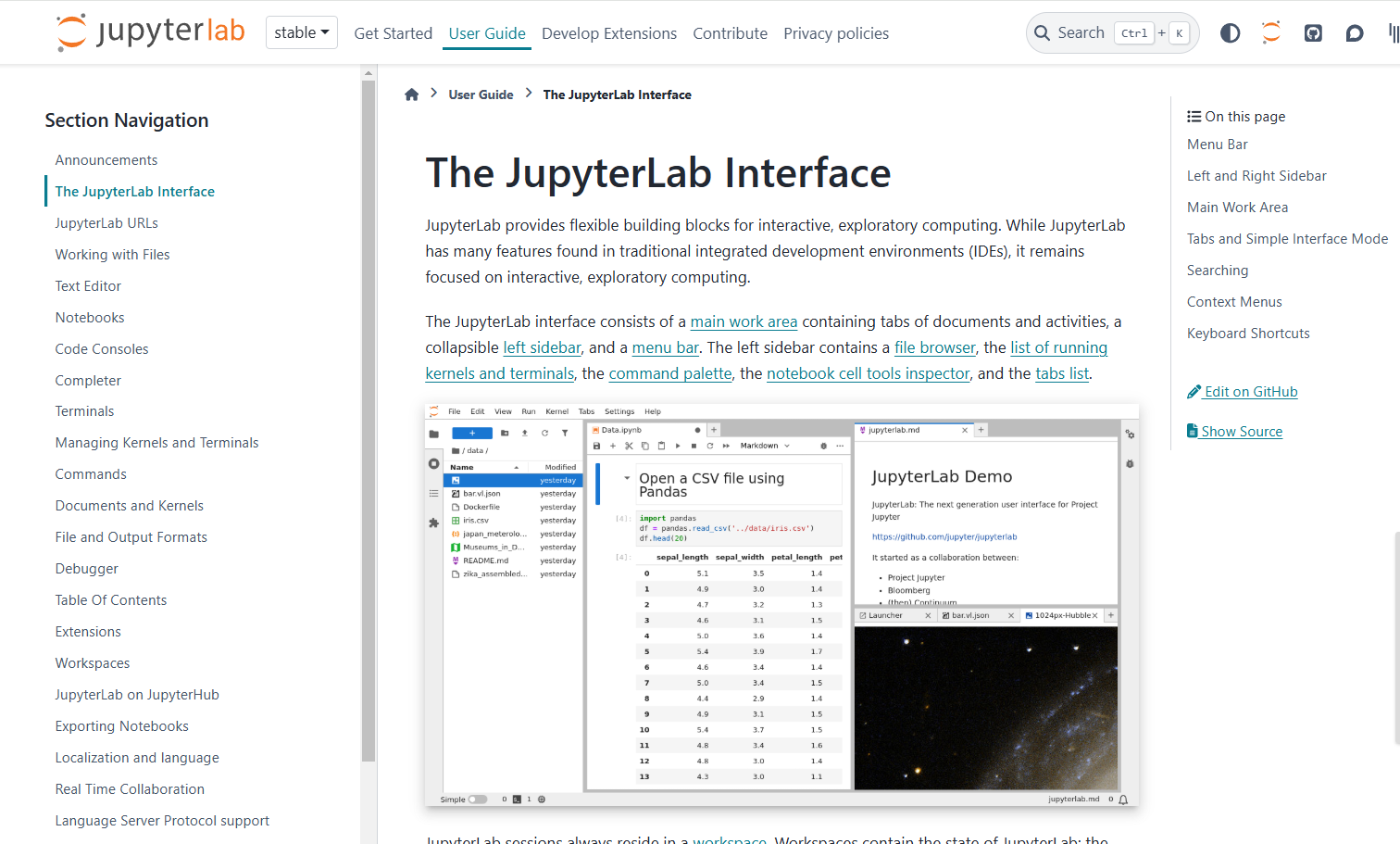
#그냥 화면만 보면 될것 같지만...이것저것 클릭해 보지 않을수 없다. ㅜ.ㅜ
#메뉴얼을 익히자.
#00_Introduction.ipynb (현재)
소개만 몇시간을 보고 있습니다. 아래 순서대로 공부하면 됩니다.
#01_ExploreData.ipynb (다음시간)
#02_PrepareData.ipynb
#03_BuildModel.ipynb
#맨땅에 헤딩은 어렵다.
#영어로 되어 있어서 더 그런것 같다.
#텍스트를 영어로 읽으나 한글로 읽으나 감흥이 없다.
#아니면 새로움에 대한 열정이 사라져 버린것인가?!
반응형
'AI study, 활용공부, 최신 tech 트렌드' 카테고리의 다른 글
| 찾아보기, n8n, 무엇에 쓰는 물건이고? (3) | 2024.12.12 |
|---|---|
| AI study, Cursor, 개발자의 생산성을 높이기 위해 설계된 AI 기반 코드 편집기 (3) | 2024.12.10 |
| 리뷰, 1인 개발자, 데이팅 앱, 전 건물주, 시스템과 루틴 등 | 조코딩의 팟캐스트 #4 (1) | 2024.12.04 |
| AI가 개발자를 대체한다?!, 드림코딩 엘리님 (4) | 2024.12.04 |
| 바라보기, 찾기, Window에서 가상 환경 만들기, 3분안에 해결하기 (3) | 2024.11.11 |